Welcome to Captcha Challenge!
The challenge description was a website, upon entering the website, you are allowed to register/sign in.
After registering and logging in, you are shown a captcha, and it seems that the challenge was to solve 500 consecutive captchas without any mistakes. However, it seems that you are able to skip captchas by refreshing the page (this turned out to be very useful).
Captchas looks like this:

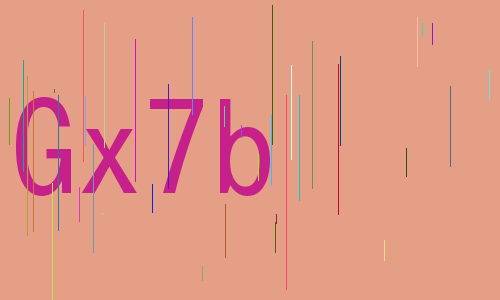
To automatically solve all 500 captchas, we wrote a python script using the Python Imaging Library. The trick to solving the captchas was to do some pre-processing and to build a dataset of good characters which we will be using to solve new captchas.
Processing
Turn background/noise to white, and text to black Scan the entire picture and rank the colours by frequency, the background colour would have the highest frequency followed by the text
Dynamically slice the image by characters
For each X coordinate, if the Y coordinates along the X coordinate has a black pixel:
set inLetter = true
Keep going along X until you reach a X where there is no black pixel along it, then you have your starting and ending x coordinate for your character!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
for y in range(im2.size[0]): # slice across
for x in range(im2.size[1]): # slice down
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
last = y
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
end = y
if end-last > 3 and end-start > 20:
foundletter=False
letters.append((start-3,end))
inletter=False
With that, you can build a dataset of characters to use for comparison:

So now, we process new captchas similarly, and slice them up into characters for comparison with our dataset.
The code for comparison is as follows:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
class VectorCompare:
def magnitude(self,concordance):
total = 0
for word,count in concordance.iteritems():
total += count ** 2
return math.sqrt(total)
def relation(self,concordance1, concordance2):
relevance = 0
topvalue = 0
for word, count in concordance1.iteritems():
if concordance2.has_key(word):
topvalue += count * concordance2[word]
return topvalue / (self.magnitude(concordance1) * self.magnitude(concordance2))
def buildvector(im):
d1 = {}
count = 0
for i in im.getdata():
d1[count] = i
count += 1
return d1
def crack(img):
im = img
im = im.convert("RGBA")
his = im.load()
v = VectorCompare()
imageset = []
for img in os.listdir('./iconset4/'):
temp = []
if img != "Thumbs.db" and img != ".DS_Store": # windows check...
imgs = Image.open("./iconset4/%s"%(img))
imgs = imgs.convert("P")
temp.append(buildvector(imgs))
imageset.append({img[0:2]:temp})
values = {}
for y in xrange(im.size[1]):
for x in xrange(im.size[0]):
values[x,y] = his[x,y]
count = {}
for j,k in sorted(values.items(), key=itemgetter(1), reverse=True):
if (k > 0 ):
if k in count:
count[k] = count[k]+1
else:
count[k] = 1
a = sorted(count.items(), key=itemgetter(1), reverse=True)
text = a[1][0]
im2 = Image.new("P",im.size,255)
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
if pix == text:
pix = (0,0,0,0)
else:
pix = (255,255,255,255)
im2.putpixel((y,x),pix[2])
guessword = ""
letters =[]
inletter = False
foundletter=False
start = 0
end = 0
last = 0
for y in range(im2.size[0]): # slice across
for x in range(im2.size[1]): # slice down
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
last = y
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
end = y
if end-last > 3 and end-start > 20:
foundletter=False
letters.append((start-3,end))
inletter=False
results = []
for letter in letters:
m = hashlib.md5()
img4 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
guess = []
for image in imageset:
for x,y in image.iteritems():
if len(y) != 0:
guess.append( ( v.relation(y[0],buildvector(img4)),x.decode('hex')) )
guess.sort(reverse=True)
results.append(guess[0])
return results
def main():
img= Image.open("image.png")
print crack(img)
if __name__ == "__main__":
main()
To achieve a 100% accuracy, we need to reject certain solutions that contains risk, to do this, we reject a solution if any of the characters has a similarity score that is less that 0.99. With this, we were able to achieve a 100% accuracy with a rejection rate of ~1 per captcha.
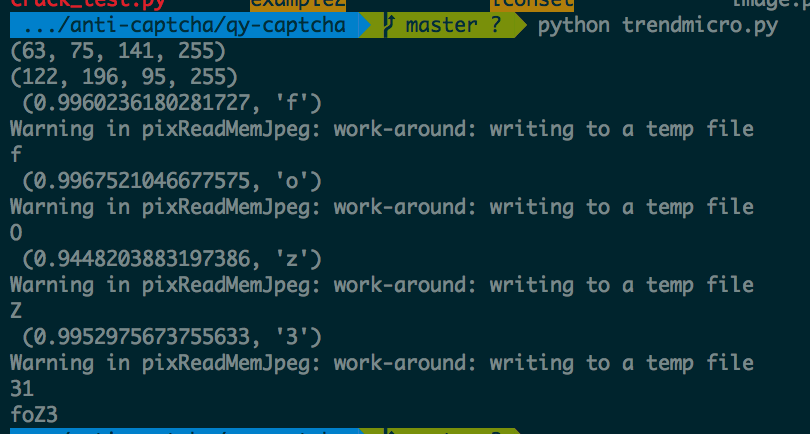
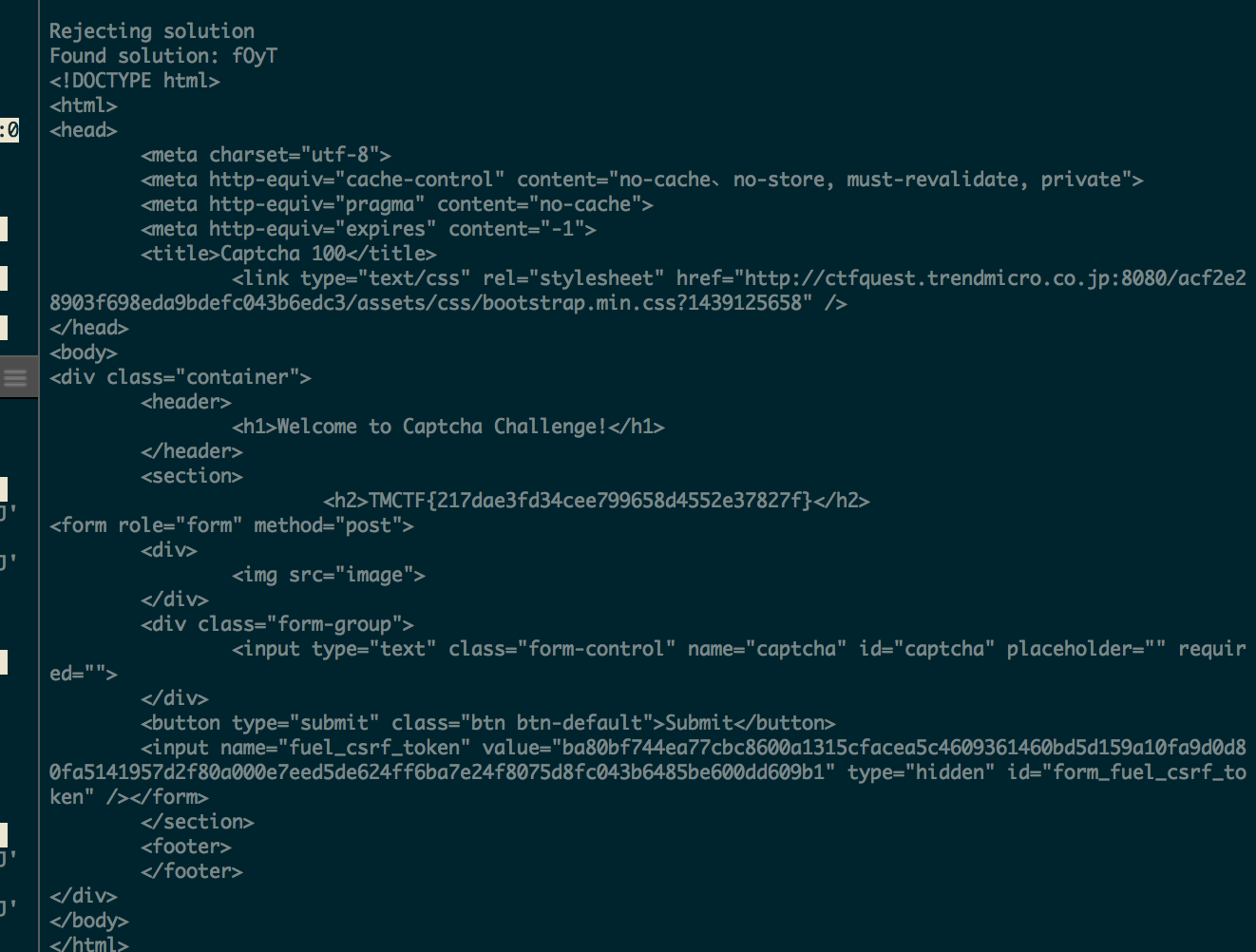
And we have our flag: TMCTF{217dae3fd34cee799658d4552e37827f}